Search technologies

A search engine is a A sequence of instructions written in a coding language that a computer can understand. that finds webpages on the A service provided via the internet that allows access to webpages and other shared files..
Search engines are used billions of times every day to find information on the world wide web.
Have you ever wondered how they can search all the available information so quickly?
Watch: How search engines find suitable webpages quickly
Find out how search engines find suitable webpages so quickly with this video from BBC Teach.
NARRATION: I'd love to book a holiday. I'd like to visit Wales and go walking. I think I'll use the internet to research my trip. I said the internet there, but actually I mean something called the world wide web. Hang on, I hear you cry, isn’t the world wide web the same as the internet?Well they are connected, but they’re not the same thing.
In the 1970s scientists developed the system of computer networks we call the internet to allow them to send messages and share their work. They tried making information pages and sharing them on the network but the pages were difficult to find and very slow to load. It wasn’t much fun. Books and papers were still easier and faster to use. Then, in 1989 a scientist called Sir Tim Berners-Lee changed everything. Tim and his team invented a language called HTML to write better pages, a set of rules called HTTP to make sharing the pages easier and the URL, an address for each page so it could be found easily. He called his system the world wide web and it grew into the huge collection of websites we know today. No wonder he became Sir Tim - what a genius!
So how is the world wide web different to the internet? Well, you could think of them both as part of a big library. The internet is the library building and all of its infrastructure, rooms and spaces full of bookshelves and cupboards and storage racks, and the corridors, lifts and stairs that connect them. The world wide web is the content of the library - the books, videos and magazines on the shelves. Each book is a website, each page is a web page.
The world wide web contains billions of pages of information with text, images, photos, videos, data. In order to find the information we’re looking for, we need the help of a computer program called a search engine. We can think of search engines as the librarians of the world wide web. In a real library the librarians create and manage a detailed list of everything kept in the library. This is called an index. Librarians spend so much time updating the index that they know what books are most popular and where to find them.
Search engines do a very similar job on the world wide web. They send out little programs called web crawlers that visit all the pages on the world wide web, making a huge index as they go. For each web page they record the web page address, this is one of Sir Tim’s inventions, it’s called the URL. They make a note of what the page is about and list the important key words. They also count links from other pages as this shows how popular that page is. These clever little web crawlers are always on the move, looking for new web pages to add to their index, and removing web pages that are no longer available.
Let’s search for information about the walking routes in Wales. I’ll use 'best, walks, Wales’ as my key search words. The search engine will use the work of those web crawlers and check the millions of entries on the index. It looks at my key search words and matches them up to the index notes about each webpage. The search engine then shows me a list of websites from its index that it thinks will be useful. The trouble is, the search engine is so good at its job it might find thousands of websites with information about Welsh walking routes. How does it decide which ones to put at the top of the list? It uses a set of rules called a search algorithm. And if you don't know what an algorithm is then I've made a handy video guide on the BBC Teach website.
The search engine uses the algorithm rules to check the thousands of websites it found in the index. There might be 200 rules to check before it decides on a page ranking, or what order to put the websites in. Some of the rules might include: Do the website pages include all the key search words? Do lots of other websites have links to this one? Is the website updated regularly? Is it quick to load? Pages with a high page rank score go nearer the top, and should be the most relevant and useful. Each search engine uses their own algorithm so you might get a different list with each search engine despite using the same search words.
It’s important to think carefully about your key search words. If I just use ‘best walks’ without adding ‘Wales’ then the search engine will look for different walks all over the world. If I spell ‘Wales’ wrong and put ‘whales’ with an 'h', then I might end up with pages of underwater videos of giant sea mammals! Those hard working algorithms need as much help as you can give them.
One last thing to remember. Companies will often pay to make sure their website goes to the top of the search list. These pages at the top of the list will usually have the letters AD, short for advert, next to them to show you that they bought their place at the top rather than by being chosen by the search engine algorithm as being useful.
So there we have it - popping down to the internet library to search the world wide web bookshelves, chatting to the search engine librarians and catching up with our old friend the algorithm. Thanks again Sir Tim and your team!
Creating a search engine index

When we enter keywords, a search engine looks through its An index contains information about the webpages that have been visited by web crawlers. Search engines look for matches in the index. for A HTML document viewed using a web browser. containing relevant information.
This index is created by Automated programs that visit webpages and collect key information such as the URL and the type of content on the page..
These are automated programs that record key information from webpages.
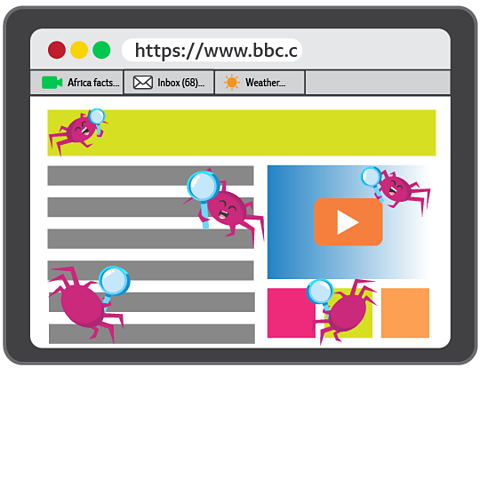
A web crawler records the webpage's Uniform resource locator, which is the address of a webpage or file on the internet. For example http://unitedkingdom.bahce.site/bitesize/primary., keywords and any links it has to other webpages.
All of this information is stored in the search engines index.
Web crawlers are constantly visiting webpages, as new content is added to the web all the time.
This makes sure that the search engine is using an up-to-date index.

Some webpages are not visited by webcrawlers.
This is because the owners of the websites have requested that these pages are not placed in a search engine's index.
Returning results

Search engines also rank the pages they find for you. They use an A precise set of ordered rules or instructions that can be followed by a human or a computer to achieve a task. to identify the pages that are most useful and place these at the top of the list.
The algorithms use ranking signals to decide which webpages will be most useful to you. These signals include:
- the number of links from other webpages to this webpage
- the number of time the keywords appear in the text on the page (although too often is a bad thing)
- the use of the keywords in the URL
- how often the webpage is updated
You might find it useful to think of this ranking as giving each page a score based on its performance in the ranking signals above. The higher the webpage's score, the higher it is ranked.
Have you ever seen the letters AD next to one of the results from a search engine?
This means it is an advert. The company has paid the search engine to place their result at the top of the list. The search engine shows AD next to the result, to let you know this.
Other ways of searching
People have been typing keywords into search bars for over twenty years. There are now other ways we can use search engines.

Some wireless devices allow us to use our voice to ask questions and use search engines to find answers.
We can also use a smartphone camera to provide a search engine with an image which it can use. The search engine can then:
- identify the image
- find similar images
- translate text in the image into different languages
- locate shops that sell the item in the image
You can even use a search engine to identify a song that is playing on your radio.
Activities
SATs preparation resources. activity
Get ready for the SATs papers with videos, activities, quizzes and games to refresh your knowledge and practise your skills.

More on Computer science
Find out more by working through a topic
- count1 of 24
- count2 of 24

- count3 of 24

- count4 of 24